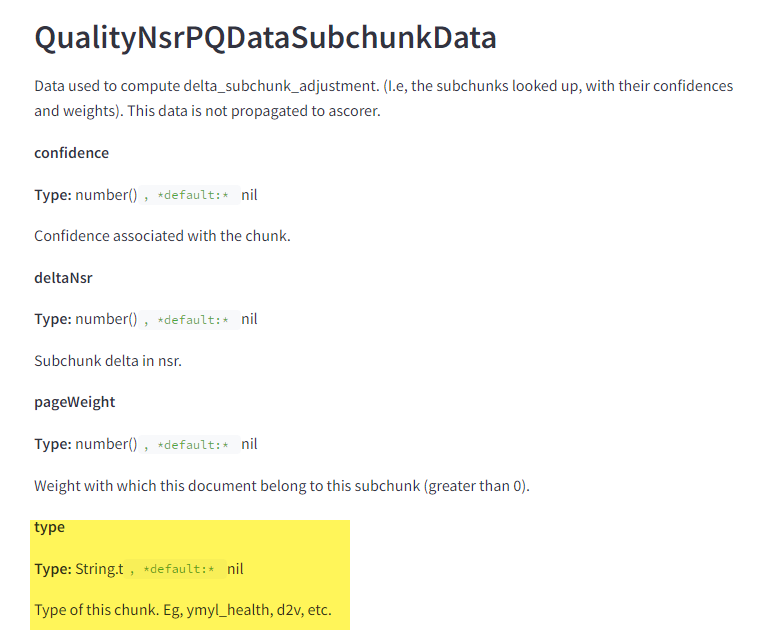
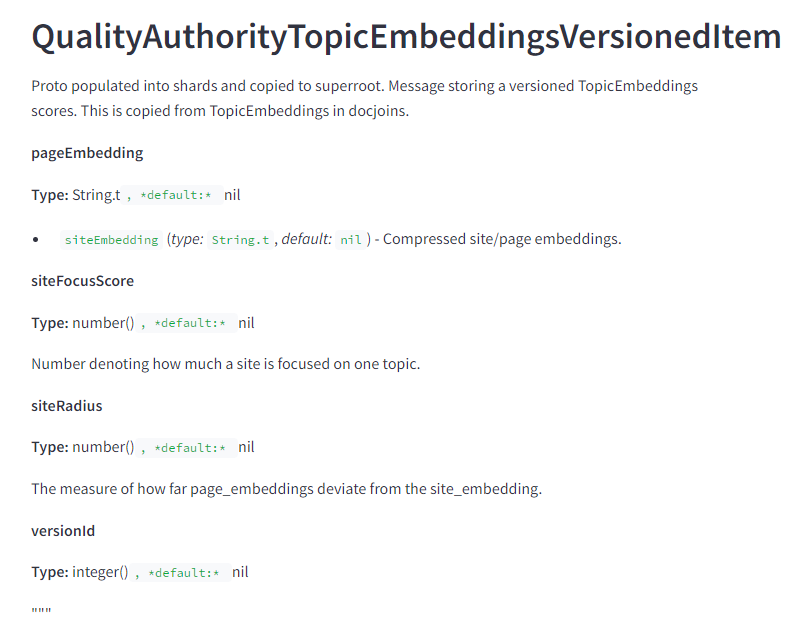
Google algoritam je procureo – Šta to znači za SEO?
Interna inženjerska dokumentacija Google pretrage je slučajno otkrivena
Ovaj tekst je izvorno sa ipullrank.com/google-algo-leak
Dodatne detalje možete pogledati i na The Verge članku, kao i na An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them.
Pregled sadržaja:
| Sekcija | Detalji | Zaključci |
|---|---|---|
| Uvod | – Interna dokumentacija Google Search’s Content Warehouse API je procurila. | – Otkrivena dokumentacija otkriva mnoge interne funkcije i mikroservise koje koristi Google za rangiranje pretraživačkih rezultata. |
| Caveats | – Ograničeno vreme i kontekst za analizu. | – Analiza je zasnovana na ograničenom vremenu i kontekstu. Dalje istraživanje može doneti dodatne uvide. |
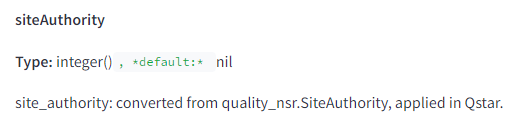
| Broj funkcija za rangiranje | – Dokumentacija otkriva 14.014 atributa i 2.596 modula koji su deo Google-ovog rangiranja. | – Veliki broj atributa i modula potvrđuje kompleksnost Google-ovog algoritma. |
| Funkcionalnosti API-ja | – Modul za indeksiranje, povezivanje, generisanje snippet-ova, i drugi sistemi. | – API dokumentacija pruža detaljan uvid u različite funkcionalnosti koje Google koristi za kreiranje SERP-ova. |
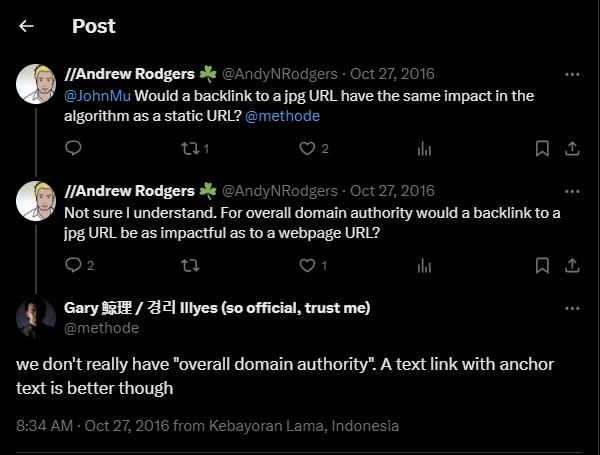
| Laži Google-a | – Google je više puta tvrdio da ne koristi „domain authority“ i klikove za rangiranje. | – Dokumentacija otkriva postojanje metrika kao što su „siteAuthority“ i NavBoost, koje koriste klikove za rangiranje. |
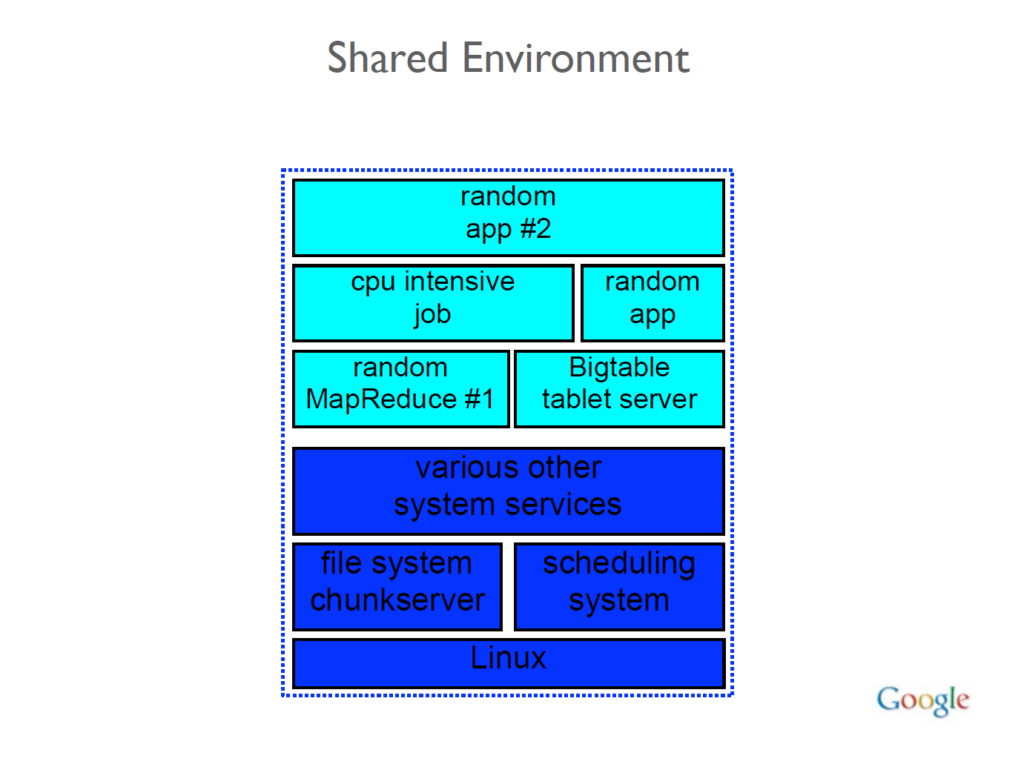
| Arhitektura rangiranja | – Google koristi seriju mikroservisa za generisanje rezultata pretrage. | – Rangiranje se vrši kroz kombinaciju različitih sistema i modula, uključujući Mustang (primarni algoritam za rangiranje) i NavBoost (re-rangiranje zasnovano na klikovima). |
| Važni moduli i sistemi | – Twiddlers, Trawler, Alexandria, SegIndexer, TeraGoogle, HtmlrenderWebkitHeadless, LinkExtractor, WebMirror, Ascorer, NavBoost, Twiddler, WebChooserScorer, Google Web Server, SuperRoot, SnippetBrain, Glue, Cookbook. | – Razumevanje ovih modula može pomoći u boljem shvatanju kako Google rangira sadržaj i kako se određene funkcije primenjuju u procesu pretraživanja. |
| Democije i penalizacije | – Anchor Mismatch, SERP Demotion, Nav Demotion, Exact Match Domains Demotion, Product Review Demotion, Location demotions, Porn demotions, i drugi democijski sistemi. | – Različite penalizacije i democije se primenjuju za poboljšanje kvaliteta rezultata pretrage i borbu protiv spam sadržaja. |
| Važnost linkova | – Linkovi su i dalje važan faktor za rangiranje. Detaljno se prate karakteristike linkova kao što su brzina spama, PageRank početne stranice, vrednost linkova u zavisnosti od nivoa indeksiranja i drugi. | – Kvalitet i relevantnost linkova su ključni za rangiranje, dok spam i neodgovarajući linkovi mogu dovesti do penalizacija. |
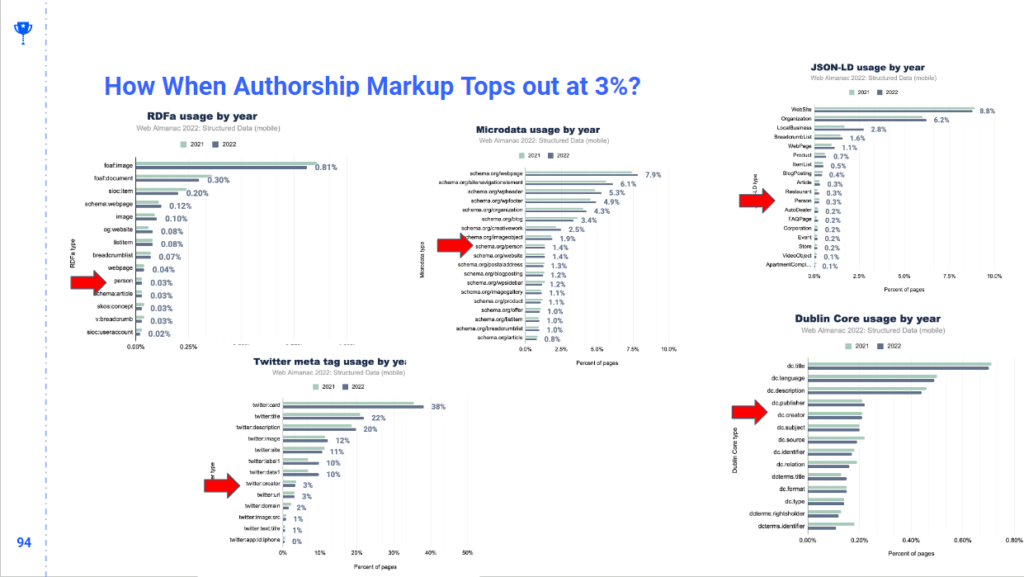
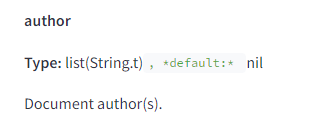
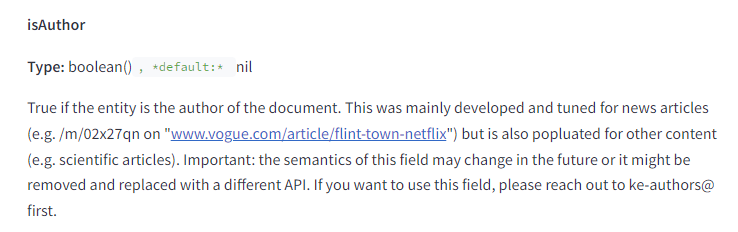
| Autorstvo i originalnost | – Autorstvo je eksplicitno beleženo i ocenjeno. | – Autorski sadržaj igra važnu ulogu u rangiranju, a originalnost i relevantnost su ključne za dobijanje visokih pozicija u rezultatima pretrage. |
| Rekomendacije za SEO | – Fokus na kreiranje visokokvalitetnog sadržaja i promociju istog. Korišćenje rezultata iz curenja dokumentacije za prilagođavanje SEO strategije. | – Preporučuje se vraćanje korrelacionih studija, eksperimentisanje sa različitim SEO tehnikama, i unapređenje kvaliteta sadržaja i korisničkog iskustva za bolje rangiranje. |
| Značaj SEO stručnjaka | – SEO stručnjaci su pokazali ispravnost mnogih svojih tvrdnji koje su bile osporavane od strane Google-a. | – Dokumentacija potvrđuje značaj SEO strategija koje su dugo bile predmet debata, kao što su važnost kliktanja, autoriteta sajta, i dr. |
Interna dokumentacija za Google Search’s Content Warehouse API je procurila. Google-ovi interni mikroservisi izgledaju slično onima koje nudi Google Cloud Platform.
Interna verzija dokumentacije za zastareli Document AI Warehouse je greškom objavljena javno u repozitorijumu koda za klijentsku biblioteku. Dokumentacija za ovaj kod je takođe zabeležena od strane eksternog automatizovanog servisa za dokumentaciju.
Na osnovu istorije promena, greška u ovom repozitorijumu je ispravljena 7. maja, ali je automatizovana dokumentacija i dalje dostupna. U cilju smanjenja potencijalne odgovornosti, ovde neću postaviti linkove, ali s obzirom da je sav kod u tom repozitorijumu objavljen pod Apache 2.0 licencom, svako ko je naišao na njega je dobio širok set prava, uključujući mogućnost korišćenja, modifikacije i distribucije.
Objašnjenje
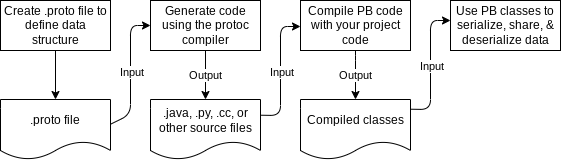
API (Application Programming Interface): Skup definisanih pravila koja omogućavaju različitim softverskim aplikacijama da komuniciraju međusobno.
Mikroservisi: Arhitektura softvera gde su aplikacije podeljene na male, nezavisne servise koji komuniciraju preko API-ja.
Apache 2.0 licenca: Licenca koja omogućava korisnicima široka prava na korišćenje, modifikaciju i distribuciju softvera, uz određene uslove.
Pregledali smo API referentne dokumente i stavili ih u kontekst sa prethodnim Google curenjima i svedočenjem o antimonopolskom postupku Ministarstva pravde. Kombinujemo to sa opsežnim istraživanjem patenata i radova za našu nadolazeću knjigu, „The Science of SEO“. Iako u dokumentaciji koju smo pregledali nema detalja o Google-ovim funkcijama bodovanja, postoji bogatstvo informacija o podacima koji se čuvaju za sadržaj, linkove i interakcije korisnika. Postoje i različiti nivoi opisa (od razočaravajuće oskudnih do iznenađujuće otkrivajućih) o funkcijama koje se manipulišu i čuvaju.
Bili bismo u iskušenju da ove podatke široko nazovemo „rangirajućim faktorima“, ali to ne bi bilo precizno. Mnogi, čak i većina njih, jesu rangirajući faktori, ali mnogi nisu. Ono što ćemo ovde uraditi je da stavimo u kontekst neke od najzanimljivijih sistema rangiranja i funkcija (barem one koje smo uspeli pronaći u prvih nekoliko sati pregledavanja ovog ogromnog curenja) na osnovu našeg opsežnog istraživanja i stvari koje nam je Google rekao/lagao tokom godina.
„Lagao“ je oštra reč, ali jedina tačna ovde. Iako ne krivimo nužno Google-ove javne predstavnike za zaštitu njihove vlasničke informacije, imamo problem sa njihovim naporima da aktivno diskredituju ljude iz sveta marketinga, tehnologije i novinarstva koji su predstavili reproduktivna otkrića. Naš savet budućim Googlerima koji govore o ovim temama: Ponekad je bolje jednostavno reći „ne možemo o tome razgovarati“. Vaša kredibilnost je važna, i kada se pojave curenja poput ovih i svedočenja kao što je suđenje Ministarstva pravde, postaje nemoguće verovati vašim budućim izjavama.
Ograničenja
Svi znamo da će ljudi pokušati da diskredituju naše nalaze i analize iz ovog curenja. Neki će se pitati zašto je to važno i reći „ali to smo već znali“. Zato, hajde da odmah rešimo nedostatke pre nego što pređemo na suštinu.
Ograničeno vreme i kontekst – Zbog prazničnog vikenda, mogao sam da provedem oko 12 sati u dubokom razmišljanju o svemu ovome. Izuzetno sam zahvalan nekim anonimnim osobama koje su mi bile veoma korisne u deljenju svojih uvida kako bi mi pomogle da se brzo uhvatim u koštac sa materijom. Takođe, slično curenju Yandex-a koje sam pokrivao prošle godine, nemam potpunu sliku. Dok smo kod Yandex-a imali izvorni kod za analizu bez poznavanja razmišljanja iza toga, u ovom slučaju imamo neka razmišljanja iza hiljada funkcija i modula, ali nemamo izvorni kod. Moraćete da mi oprostite što ovo delim na manje strukturisan način nego što ću to učiniti za nekoliko nedelja nakon što se detaljnije upoznam sa materijalom.
Nema funkcija bodovanja – Ne znamo kako su funkcije ponderisane u različitim nizvodnim funkcijama bodovanja. Ne znamo da li se sve dostupne funkcije koriste. Znamo da su neke funkcije zastarele. Osim ako nije eksplicitno navedeno, ne znamo kako se stvari koriste. Ne znamo gde se sve dešava u lancu obrade. Imamo niz imenovanih sistema rangiranja koji se labavo usklađuju sa načinom na koji ih je Google objasnio, kako su SEO stručnjaci primetili rangiranje u praksi i kako ih patentne prijave i IR literatura objašnjavaju. Zahvaljujući ovom curenju, sada imamo jasniju sliku o tome šta se uzima u obzir, što može informisati na šta da se fokusiramo u SEO-u u budućnosti.
Verovatno prvi od nekoliko postova – Ovaj post će biti moj inicijalni pokušaj analize onoga što sam pregledao. Možda ću objaviti naknadne postove dok nastavljam da istražujem detalje. Pretpostavljam da će ovaj članak dovesti do toga da SEO zajednica požuri da analizira ove dokumente i mi ćemo kolektivno otkrivati i rekontekstualizovati stvari mesecima koji dolaze.
Čini se da su ovo aktuelne informacije – Koliko mogu da procenim, ovo curenje predstavlja trenutnu, aktivnu arhitekturu Google Search Content Storage-a od marta 2024. godine. (Da preskočimo reakciju Google PR-a koji će reći da grešim. Zapravo, hajde da preskočimo tu igru, ljudi). Na osnovu istorije izmena, povezani kod je postavljen 27. marta 2024. godine i nije uklonjen sve do 7. maja 2024. godine.




![The image is a slide titled "Realtime Boost Signal" with a link to (go/realtime-boost). The content of the slide includes information on the sources and uses of real-time boost signals, as well as graphs illustrating query trends. Here are the details: Title: Realtime Boost Signal (go/realtime-boost) Spikes and Correlations on Content Creation Location (S2), Entities, Salient Terms, NGrams... Sources: Freshdocs-instant Chrome Visits (soon) (highlighted in yellow) Instant Navboost (soon) Not restricted by Twitter contract Run in Query Rewriter: Can be used anywhere: Freshbox, Stream... Graphs: Top Right Graph: Titled "Twitter Hemlock Query Trend" with a red line indicating "Noise level (median + 1IQR)" and a spike indicated by an arrow labeled "Spike." Bottom Right Graph: Titled "Query [Dilma]" with the caption "Spike 5 mins after impeachment process announced." It shows a spike in the score time series for the term "Dilma." At the bottom, the slide has a note saying "No birds were hurt in the making of Realtime Boost signal," and the Google logo is displayed in the bottom left corner.](https://ipullrank.com/wp-content/uploads/2024/05/image16-1024x576.png)
![The image is a diagram titled "a sample of ML across the company" and shows how machine learning (ML) is integrated into various Google and Alphabet products. The diagram illustrates connections between different ML teams and products, with circle size proportional to the number of connections. Title: a sample of ML across the company Subtitle: Machine learning is core to a wide range of Google products and Alphabet companies. Components: ML Teams (green circles): Sibyl Drishti Brain Laser SAFT Alphabet companies (red circles): [X] Chauffeur Life Sciences Google products (yellow circles): Nest Search Indexing Android Speech Geo Play Music, Movies, Books, Games Image Search G+ GDN Context Ads YouTube Search Translate Email Inbox Play Apps Product Ads GMob Mobile Ads Google TV Security Google Now WebAnswers Genie Connections: Lines connect various ML teams to multiple Google products and Alphabet companies, indicating collaboration or integration of machine learning technologies. For example, the "Brain" ML team connects to numerous products such as Nest, Search Indexing, Android Speech, Geo, YouTube, and Translate, among others. The "Laser" team connects to products like Google TV, Security, Google Now, and Play Apps. Legend: Green circles: ML team Red circles: Alphabet companies Yellow circles: Google products Circle size is proportional to the number of connections Logo and Disclaimer: Google logo at the bottom left corner "Confidential & Proprietary" note at the bottom right corner This diagram visually represents the extensive integration of machine learning across various products and services within Google and its parent company Alphabet.](https://ipullrank.com/wp-content/uploads/2024/05/image19-1.png)













![The image displays a section from a technical documentation page. It includes the following elements and text: encodedChardXlqYmylPrediction Type: integer(), default: nil An encoding of the Chard XLQ-YMYL prediction in [0,1].](https://ipullrank.com/wp-content/uploads/2024/05/image35.png)